Batch Process in AWS - Part 3 - What's the REAL solution?
If you haven't already read the previous blog, start here.
A video to go along with it can be found on my YouTube channel.
My previous solution with an atomic counter in DynamoDB didn't work, so what's the real solution?
Step Functions
I revisited the Step Functions solution. Re-writing my Batcher and Processor functions to use Step Functions and a distributed map was pretty easy. I had to use a distributed map because an inline map could never handle 100k records.
A couple of tests later and it would clearly work.
DynamoDB and the itemState record
In the previous post I mentioned how option 6 wouldn't work because counting up to see if 100k records had been written wasn't an efficient process and would end up costing a lot.
But what about going the other way?
What if instead of counting how many itemState records exist for a batch, I instead removed them as they were
processed
and then counted how many were left.
In fact, I wouldn't have to count how many were left, I'd just have to check to see if at least one was left.
This would make reading the table to see if the batch was complete very cheap.
I can do it with just a simple query and a LIMIT 1:
const item = await ddbClient.send(new QueryCommand({ TableName: process.env[TABLE_NAME_KEY]!, Limit: 1, KeyConditionExpression: 'pk = :pk', ExpressionAttributeValues: { ':pk': message.batchId, }, }));
Now I just need to put this into a polling routine and I can easily check to see if the batch is complete. Once that query comes back empty, the batch is done.
So now came the question about how to poll for this. Whenever I think of polling I think of cronjobs and EventBridge Rules with cronjob expression. But managing that rule, both turning it on when the batch started and off once the batch was complete felt cumbersome. I wanted some more elegant.
I looked into Event Bridge Scheduler, and this is a pretty slick solution that allows me to easily set up a repeating invocation of a Lambda function. It also let's me set a time window for the rule to be active, after which polling stops.

But, this doesn't feel great. Best option I can see is to track the execution times of batches and then set this window to be a little longer than the previous run. That feels brittle.
SQS can come to the rescue here. I had never found a reason to use it before, but you can put a delay on messages you publish. This means I can start the batch and put a message in the queue that won't get delivered for 5 minutes. A Lambda function subscribes to that queue and then checks the table for batch completion (the batchId is in the message). If the query comes back with at least one record, it writes a new message to the queue with another 5 minute delay.
if (item.Count === 0) { // if no records exist, the batch is complete console.info('The batch is complete!'); // do something with the batch } else { // if one record exists, the batch is not complete console.info('The batch is not complete, waiting 5 minutes and then will check again'); // put another message on the queue having it checked again in 5 minutes await sqsClient.send(new SendMessageCommand({ QueueUrl: process.env[QUEUE_URL_KEY]!, MessageBody: record.body, DelaySeconds: 5 * 60, // 5 minutes })); }
What's especially fun about this is I could write some complexity into this delay.
For example, I could track the batch execution times and then set the delay to be the average execution time of the batches. Maybe that number is 4 minutes. If the batch isn't complete, the next check could occur at a different interval, 1 minute.
This gives me an opportunity to minmax the polling so I can get it to register the completion as soon as possible after the batch is complete while minimizing how many times I actually poll the database for completion. It feels like the best of both worlds. Additionally, because I have to actively schedule the next execution then runaway polling isn't possible, although NOT catching a batch being complete could be an issue if the next message to the queue fails to publish.
But, having not implemented this in a production system yet there could be some edge cases which could cause failures. I'd love to hear what you think. Reach out to me on LinkedIn with your opinions.
Costs
This is where things get really fun. /s
Let's compare these two methods using a batch of 100k items.
Step Function
Pricing a Step Function execution with a distributed map is complicated. I started by looking at Example 5 on AWS's pricing page. The state machine I created was very similar to the example:
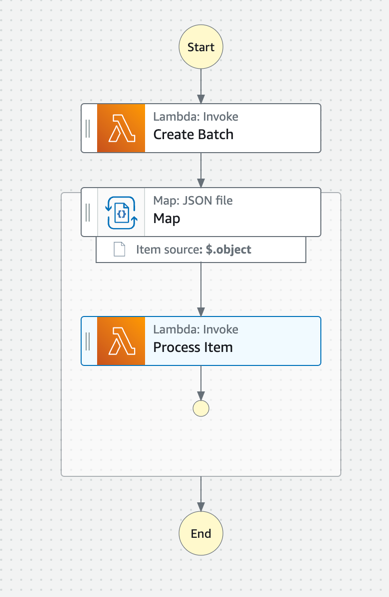
When it came to calculating the actual costs of an execution I reviewed this pricing example and adjusted few numbers.
State Transition charges
100,005 - 4000 = 96,005 transitions
State Transition charges = 96,005 * $0.000025 = $2.40
Express Request charges
The price per million requests in the US East (N. Virginia) is $1.00 Request charges = 100K/1M requests x $1.00 = $0.10
Express Duration charges
The price for the first 1,000 GB-hour in the US East (N. Virginia) is $0.0600.
I set the batch size on the distributed map to 100, so with 100,000 records that means I'll have 1000 iterations. Additionally, I can see after reviewing a sample run that the total invocation time was 77,588,242ms. This is 77,588 seconds or 21.55 hours.
77,588 seconds * 64MB / 1024 = 4,849.25 GB-seconds or 1.347 GB-hours
Duration charges = 1.347 GB-hour x $0.0600 = $0.081
Total Charges
Total charges = $2.40 + $0.10 + $0.08 = $2.58
Ok, not so bad. Even if we run this each day for the month we're talking under $100.
However, I don't trust my math and there doesn't seem to be a way to properly control how much memory each express step uses. I assumed 64MB, but it could be more. I ran one execution of 100k records one day and checked back in Cost Explorer.
It reports $4.24 for that execution.
That's a difference of $1.66. I honestly don't know where this discrepancy comes from. If you do, please let me know.
SQS and DynamoDB
But what are our costs with SQS and DynamoDB?
There are three areas we have to consider. SQS, DynamoDB, and Lambda.
SQS
SQS pricing is super simple, and the free tier is so high that per-batch is free, but in this case there will be (at most) 3M messages per month.
That's if I didn't group anything at all (if you recall from the first post, I put multiple items in each message, effectively working like what Step Functions does with the distributed map.
But since I batch multiple items per SQS message that reduces the total message count to under 1M records a month and that means not paying a penny, since the first 1M requests are free.
If a lot of these processes were built and I went over the free tier, it's $0.40 per million messages, or $0.04 per run.
DynamoDB
DynamoDB pricing is a little more complicated to calculate, but generally straightforward. I'm using on-demand pricing since the workload is so bursty.
On-demand pricing is $1.25 per million write request units.
100k/1M writes * $1.25 = $0.125
Deletes will also cost about $0.125.
Read pricing is $0.25 per million read request units. Let's assume I only have to read the batchState item 5 times.
5/1M reads * $0.25 = $0.000125 (let's just call that free)
There are also data storage costs. Each item is about 150 bytes or less, so let's call all 100k items 15MB. DynamoDB gives you the first 25GB for free.
Lambda
We can estimate the same Lambda invocation costs from the Step Function example.
$0.0000166667 for every GB-second and $0.20 per 1M requests
For invocations: 100k requests * $0.20 = $0.02
For runtime memory: 100k requests * 77,588 seconds * 64MB / 1024 = 4,849.25 GB-seconds or 1.347 GB-hours
Total: 1.347 GB-hour * $0.0000166667 = $0.00002245
Total Charges
Total charges = $0.25 + $0.02 + $0.00002245 = ~$0.27
Conclusion
The Step Function solution has better observability and is a simpler solution, but it's more expensive.
$3.31 (SFN) vs $0.27 (SQS) is a big difference.
And these are pretty baseline costs because the Lambda invocations that process the individual items are taking almost no memory and running relatively quickly. Real world work is probably going to take longer to process and require more memory. However, those costs scale the same for both solutions.
So, since SQS is cheaper, you should use that, right?
I'm not so sure. I had to put a lot of extra code into the processor and finalizer to make things work with the SQS solution. There is a cost to that too, something you can't easily quantify using the AWS pricing calculator.
Here's how I'd break it down:
Do you have only a few of these pipelines you have to build? Then use Step Functions.
The extra runtime cost is worth the simplicity of the solution. There's much less code you have to build
However, if you're going to be building dozens of these pipelines, like you're a large enterprise that is standarizing on a process, then putting the extra engineering effort into SQS can yield the best results.
The latest code is available in the GitHub repository