Batch Process in AWS - An Exercise in Nuance
Updated (2024-09-21): There is a second video that explains why the atomic counter described here won't actually work.
Recently I was helping a client with a batch processing problem in AWS. They needed to run a process against each item in a database. They originally ran this process in their kubernetes cluster, but it was too slow and wasn't parallelizing well.
If you'd rather watch a video about this, you can check it out here:
We decided to move the process to AWS, and I suggested using SQS and Lambda Functions. It worked well and they were happy with the results.
A couple months later they asked me how to be alerted when the process finished. Hmm...
I started with searching around and found some articles that covered the subject.
- https://www.ranthebuilder.cloud/post/effective-amazon-sqs-batch-handling-with-aws-lambda-powertools
- https://aws.amazon.com/blogs/compute/understanding-how-aws-lambda-scales-when-subscribed-to-amazon-sqs-queues/
- https://betterprogramming.pub/sqs-batch-processing-with-reporting-batch-item-failures-6c405c852401
- https://medium.com/theburningmonk-com/whats-the-best-way-to-do-fan-out-fan-in-serverlessly-in-2024-2f8b5cb04b9f
But they either didn't cover the problem I was trying to solve, or they didn't go into the detail I was hoping for.
I set out to find an answer and I had some specs in mind:
- Uses Lambda and SQS (standard or FIFO) as a cost-effective manner to handle parallel processing
- Notified when the batch is complete, either by EventBridge event or something similar
- Items are not naturally idempotent, meaning the downstream processing of the item needs to be safe from duplicates. Think an email service which would does not easily catch duplicate items.
- Items can be processed out of order
While Yan's article covered using Step Functions to accomplish some parallel batch processing, Step Functions can get very expensive very quickly. For this use case, it wouldn't be very cost effective.
Everything I was reading reminded me of the Draw the Rest of the Owl meme:

The Proof of Concept
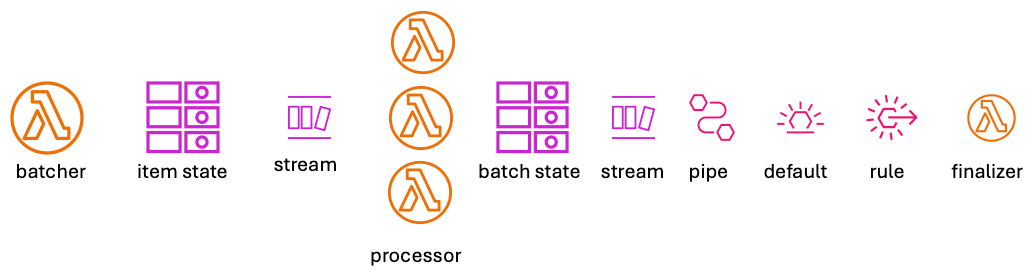
I dug into some code for a few hours and found something that worked well. I'll walk through each component and go into more details than you get with a couple of circles.
The Batcher
This is a Lambda function that is responsible for determining which items need to be processed and writing to the SQS
queue for processing.
Each item has a batchId and an itemId.
The batchId is used to group items together and the itemId is used to identify the item in the batch.
Each item gets any additional information needed for processing.
This should be relatively small and, of course, needs to be less than the 256KB limit for SQS messages.
In the POC code I built the only additional value I used was value, which is a random number between 1 and 1000.
I'll cover later how this value is used.
Now, if you look at my POC code you're going to notice that each message written to the SQS queue has more than one item, instead each message has an array of items to process. This is a habit I've gotten into when working with SQS and Lambda, as it allows me finer control over the batch size and the number of Lambda invocations. Since Lambda functions can only be invoked with a maximum of 10 messages from a queue, this allows me to have each Lambda invocation process more than 10 items at a time by loading more than one item in each message. This is a trade-off, as it can make the Lambda function more complex, but it can also gives me an easy option to tune performance later by either increasing or decreasing the runtime of the downstream processing Lambda functions. Of course, your mileage may vary.
There is one final piece to the batcher, and that is the batchState item in DynamoDB.
It has the batchId as the PK and status as the SK and a remaining attribute.
The remaining attribute is set to the number of items in the batch when the batch is created.
This record will be used later to determine when the batch has completed processing and is the key to the solution.
Originally, I had tried allowing the downstream processing Lambda function to update the batchState item by first
incrementing the remaining attribute before processing an item and decrementing it once it was complete.
However, I found there were too many edge cases where the remaining attribute could be zero even though there were
items that still needed processing.
The Ingestion Queue
This is an SQS queue that the batcher writes to and the processor subscribes to. I didn't want to constrain the solution to only using a FIFO queue, so I used a standard queue as it made the problem more difficult since it's a +1 delivery mechanism and idempotency wasn't guaranteed.
The Processor
This is a Lambda function that processes the items in the SQS queue with a normal SQS event source used to drive the
Lambda function execution.
The Lambda function processes each item in the batch and then updates the batchState item in DynamoDB, decrementing
the remaining attribute by one.
Didn't account for failures
Updated (2024-09-21)
The atomic counter as currently written WILL NOT WORK properly, as 500 errors from DynamoDB will cause the remaining
attribute to be decremented more than once.
But, for now, let's continue on like this would have actually worked =-/
In the POC, the processor simulates processing work by sleep for the value number that was generated by the batcher.
One thing that comes with using a standard queue and not a fifo queue is
the +1
processing problem.
To handle this, a itemState item is written to the DynamoDB table to hold information about the item being processed.
The partition key is the batchId and the sort key is the itemId.
Additionally, a status attribute is used to track the status of the item.
Initially this is processing but can also be failed or finished.
Before an item is processed from the queue, the itemState record is written to DynamoDB and if the status is already
processing, then it's considered an ignorable item as a result of the +1 delivery and is skipped.
If the status is anything else, it's considered a safe item to reprocess.
If any item fails to process, the itemState record is updated to a 'failed' status and the message is returned to the
queue.
There is one issue with this, and that is the message will be returned to the queue and processed again, but not just
the
one item that failed, but all items in that message.
This is the one downside to putting an array of items in the message instead of just one.
The itemState record will prevent the other items from being processed, but it's still a bit of a waste.
This allows for automatic retries for transient failures, but it's not perfect.
If I was using a FIFO queue, I wouldn't need this itemState record at all. This is a good argument for using a FIFO
queue vs a standard queue as it reduces complexity and the number of problems that can occur.
The Finalizer

The finalizer is used to react when the batch is complete.
The batchState item is updated with each item processed and when the remaining attribute is zero, the finalizer is
invoked.
A Lambda function with a DynamoDB stream as an event source with a filter on the remaining attribute being zero could
be used to accomplish this.
However, that's not very fun and as someone once told me
if you can avoid using Lambda functions, you should (paraphrasing Eric Johnson).
So, instead I chose to use EventBridge pipes.
A source of the DynamoDB stream then gets a filter on remaining == 0 and then sends a message to an EventBridge
default bus.
It could easily send the message to an SNS topic or may other services. But, I picked to play a little with custom
EventBridge messages.
Just as a test to make sure it's working properly, I subscribed a Lambda function to the EventBridge bus with a rule
looking for the custom message published by the pipe.
Variants
I've tested this out numerous times, and it seems to work just fine.
Just because it works, doesn't mean the work is done.
It's always worth reviewing, especially with a clear head and the blinders off, to make sure you can't make things better. Sometimes this means rubber ducking with someone, and thankfully I have a wonderful network of colleagues. I showed this to a few and got some great feedback and developed a few alternatives.
Use DynamoDB state item as queue item
As Jeremy Daly pointed out,
I have two persistent data stores in my solution, SQS and DynamoDB.
I don't need both.
Instead, I could skip SQS and the batcher would write the itemState and batchState items directly to DynamoDB.
The processor Lambda function would use DynamoDB (with a filter) as an event source instead of SQS.
Don't use the batchState item and query a GSI instead
Another option would be to avoid the batchState item and instead use a GSI on the table.
A poller would need to be introduced to check for the completion of the batch.
This would reduce the need for a batchState item, and removing things is generally good.
However, there is that trade-off of adding a poller, and starting and stopping that poller could introduce some
complexity that would offset the benefits of removing the batchState item.
FIFO queue and groups
If I used a FIFO queue, I could take advantage of the MessageGroupID field to introduce some
scaling benefits.
In this case, the processor Lambda function will only invoke once per group, allowing you to control exactly how
many Lambda functions are running at once.
This can be a simpler method than trying to control the number of Lambda functions running with a standard queue
and the concurrency options available in the Lambda function.
Conclusion
Solving for batch completion notifications was a fun challenge and I'm happy with the solution I came up with. I found there to be a more nuance and complexity than I originally thought, and I'm happy I took the time to explore the problem in depth. I hope you got something out of this. If you'd like to see all the code, it's available on GitHub.