A Simple Event Source Based API Microservice and the AWS CDK
Microservices have been pretty hot lately. If you don't already know that I probably won't convince you in this blog. While they aim to solve problems of highly distributed services, they bring about new challenges. One of the most prominent that I've been seeing is the lack of treating other aspects of the software development lifecycle in micro sizes.
Take the CI process, this is normally something you set up once, and you rarely have to revisit. However, when you have microservices, that CI pipeline is something you have to put more resources into. You can create one pipeline that is flexible enough to handle deploying all the microservices (and you have to come back and make changes from time-to-time as new microservices are created) or you can create a pipeline for each microservice, customized as needed for that particular microservice.
I've seen what happens when you take the former approach, and I've had to manage one pipeline for over 100 microservices... it's not great, and not pliable for the needs of the application as a whole. If you're building microservices, you should have micro CI pipelines too. However, having a lot of pipelines and their respective code requires skillful reuse of pipeline definitions. Traditional IaC solutions like CloudFormation and Terraform don't always lend well to that work. You're likely to end up with a lot of copy-pasta'd code that's difficult to maintain properly.
On a previous project we faced these issues when trying to create a suite of reusable Terraform modules for our organization to leverage with new customers. We got a long way with Terraform, but some featured we needed were going to require putting a generation layer in front of it. This way we would call a generator with a few simple parameters that would spit out a Terraform module that would have exactly what we needed without having to pull any tricks.
But this is where the AWS CDK steps in. For a while I've wanted to build a microservice for a simple Event Sourced API. I was having a hard time getting into a position where I felt it was reusable for my needs. But after exploring the AWS CDK I found it was able to perfectly deliver on my vision for the API. Hopefully you find this API interesting for either what it does or how it gets deployed.
What it does
Specifically, what it does is provide a simple REST-style API for public consumption that uses a light version of Event Sourcing for the data model. If you aren't familiar with Event Sourcing, I suggest a quick review of Martin Fowler's definition. Much of what I know came from his definition. This API only implements a very small part of Event Sourcing as a whole. The goal is to get one of the core concepts of ES implemented easily, as everything else builds upon it. This API provides the core, and you are expected to extend it to your needs.
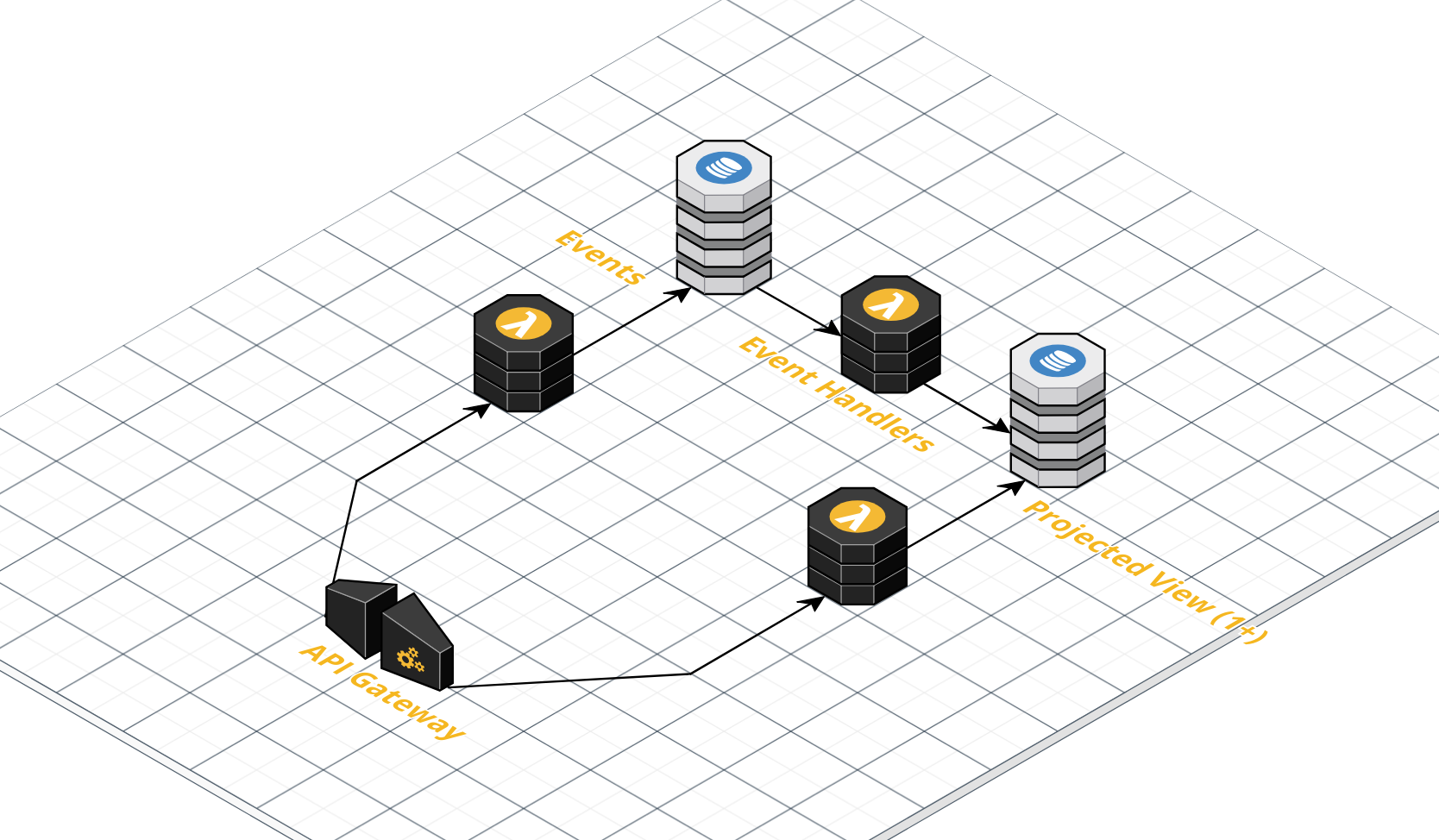
First, a quick review of the architecture. More details can be found in the source code' s README.
screenshot courtesy of CloudCraft
API Gateway exposes an endpoint. POSTs go to one lambda and GETs go to another. There are no PUTs or DELETES, as the functionality typically associated with these methods are instead handled via new events to the POST. The POSTs will hit a Lambda that writes the body of the POST to an 'events' table in DynamoDB. A DynamoDB Stream will trigger another Lambda that will process that event against one or more project views. Later, a client will use a GET to read one of those projected views.
| HTTP Method | Path | Description |
|---|---|---|
| POST | / | creates new event record in table |
| GET | / | gets 10 'default' records |
| GET | /{id} | gets 'default' record by id |
| GET | /{view_name} | gets 10 '<view_name>' records |
| GET | /{view_name}/{id} | gets '<view_name>' record by id |
That's it. Very simple. As you need to add components (e.g. emailers, notifiers, reporters, etc.) onto this system it will be handled by adding your own Lambdas onto the various DynamoDB streams. Developers can add their own projected views into the system by simply adding new handlers into the codebase. Just extend one point in the index.ts.
For consistency, I recommend following the pattern laid out by having each set of the event aggregators (what builds the projected views from the event stream) represented by its own module, as 'default' is.
Remember that 'default' is an explicit name, and the first projected view you get in the system 'for free'. You can, * and should*, modify this to your needs by editing the files and tests in the default directory. If working as designed, you shouldn't have to edit any files outside of the events directory during normal development work (the O in SOLID).
For a reference point on adding additional projected views, please see the secondary-aggregator branch.
This only gets you a very simple and trimmed down version of an Event Sourced API model. I wanted to start small and made some design decisions accordingly. If you plan on using this, I recommend you understand the following:
Not using AWS Integration with API Gateway and DynamoDB
The first iteration of this API used API Gateway's API Integration to have API Gateway talk directly to DynamoDB. I liked this setup because it removed a component (always good) and reduced overall costs (always good) and sped up the API (yay!). However, the cost was that you would need to implement all of your normal business logic - like event validation, defaulting values, error handling - directly in this integration configuration, and it was too limiting for most of my needs. I could forsee situations in the near future that would be difficult to implement with these tools. I would have to fallback to a Lambda anyway. Perhaps in the future this will be an option to the CDK package. If you needs mean you can remove the Lambda and go straight to DynamoDB, please do.
My naming conventions are probably bad
I can't really say I've named everything well. If you think the projected views or aggregators are really something else, please submit a PR. I'm glad to make changes. As they say, there are only 2 hard problems...
How it does it
At the AWS NY Summit AWS announced the General Availabilty of the AWS Cloud Development Kit, the CDK. I had been using it for a couple months before, starting around 0.30.0. I was very excited to see it hit GA as it meant a few things. First, it meant the API had stabalized! Second, it would start to the get recognition I felt it deserved in the community. The CDK provides a powerful method for creating Cloudformation Templates that beats any other system out there.
The CDK means you get to write Infrastructure as Code as Typescript or Python (or others) instead of static YAML/JSON. That code is then synthesized into traditional Cloudformation templates.
This provides a few advantages. First, it allows you to write complex logic and functionality to create more robust and useful IaC modules. I've used straight CloudFormation files and it's difficult to build complex templates that are reusable. I've also used Terraform which allows for some additional complexity, but not on the level the CDK provides. Earlier I mentioned we had run into some limitations of Terraform and considered putting generation in front of it. If we had, I imagine it would have looked a lot like the CDK, but without nearly the power.
For example, if you want more projected views, you just add the handlers to the Lambda code and the CDK picks it up automatically and deploys all the right AWS resources accordingly. Normally this would require some sort of automated ( that you'd likely have to write) or manual maintenance (that you'd definitely have to write) to get your state updated.
If you're writing Cloudformation Templates for your infrastructure, you owe it to yourself to look at the CDK.
In Conclusion
I've been a big proponent of the Event Sourced data model. I've used a slimmed down version in a number of projects the last couple of years and always been pleased over a traditional "CRUD" model. It doesn't take a lot of complexity before you can reap a lot of the rewards. I found myself re-implementing the same thing a couple of times, so it made sense to refactor it into a reusable api. I struggled with doing it with CFN or Terraform, as neither allowed me the flexibility to build what I needed to be truly reusable.
And since I believe that good software development should also include good processes, I added in the CicdStack, which you can execute against your own AWS account to create a CodePipeline pointed at a Github repo. It will pull, build ( run `cdk synth`), and deploy through CloudFormation. Normally CFN templates for CodePipeline can get very tedious and painful to write, due to the complexity. Thanks to the CDK, 130 lines of Typescript code turns into 1000 lines of a CodePipeline CFN template! That's a huge value!
The AWS CDK made the API reusable a piece of cake instead of requiring more hours than the actual API.